
How RunAnywhere SDK Powers On-Device AI Coaching in PickleRite
A deep-dive into running a pickleball-specialized LLM entirely on your iPhone

Pickleball is the fastest-growing sport in the US. But improving at it usually requires one thing most players don’t have access to: a coach who watches every session. PickleRite is a performance tracker that closes that gap — and the secret weapon behind its AI coaching is the RunAnywhere SDK, which lets us run a specialized language model directly on-device, on every iPhone, with zero network dependency.
This article walks through exactly how we integrated RunAnywhere into PickleRite, why it outperforms a general-purpose model for our use case, and what the developer experience looks like end-to-end.
What Is RunAnywhere?
RunAnywhere is an SDK for Apple platforms that enables local LLM inference on iPhone, iPad, and Mac. It supports multiple inference backends — including `LlamaCPP` (for GGUF models with Metal GPU acceleration), `ONNX`, and `WhisperKit` — and exposes a clean Swift API that integrates with Swift Conurrency.
The package breakdown in PickleRite:
runanywhere-sdks
├── RunAnywhere — core SDK, API surface
├── RunAnywhereLlamaCPP — GGUF model inference via llama.cpp + Metal
├── RunAnywhereONNX — ONNX model runtime
└── RunAnywhereWhisperKit — Whisper-based speech recognition
For PickleRite, we use `RunAnywhere` + `RunAnywhereLlamaCPP`. The LlamaCPP backend leverages the iPhone’s Metal GPU for hardware-accelerated inference on quantized GGUF models — meaning even a 350M-parameter model runs fast enough for real-time coaching feedback.
The Model: LiquidAI LFM2 350M
The model powering PickleRite’s AI coaching is **LiquidAI’s LFM2 350M**, specifically the `Q4_K_M` quantized variant hosted on HuggingFace
Why this model?

At 250 MB, the model fits comfortably in device RAM and loads in seconds. For a sports coaching app, we don’t need GPT-4-scale reasoning — we need fast, focused, domain-specific output . LFM2 350M delivers exactly that when combined with well-engineered prompts.
SDK Setup: Initialization and Model Registration
import RunAnywhere
func initliazeRunAnyWhere() {
do {
let config = Config.loadConfig().runAnywhere
// Initialize the SDK with your API key and environment
try RunAnywhere.initialize(
apiKey: config.apiKey,
baseURL: config.baseURL,
environment: .production
)
// Register the LlamaCPP backend (enables Metal GPU acceleration)
LlamaCPP.register()
// Register the specific model we want to use
if let modelURL = URL(string: config.modelURL) {
RunAnywhere.registerModel(
id: config.modelId, // "lfm2-350m-q4_k_m"
name: config.modelName, // "LiquidAI LFM2 350M Q4_K_M"
url: modelURL, // HuggingFace GGUF URL
framework: .llamaCpp,
memoryRequirement: Int64(config.memoryRequirement) // 250 MB
)
}
} catch {
print("RunAnywhere initialization failed")
}
}The memoryRequirement parameter lets RunAnywhere make informed decisions about whether the device can safely load the model — a critical safety valve for memory-constrained devices.
Model Download and Loading with Progress Streaming
The model GGUF file is downloaded once and cached on-device. On subsequent launches, RunAnywhere serves it from the local cache without re-downloading. The loading flow streams download progress, making it trivial to build a loading UI:
func loadModel() {
let modelId = Config.loadConfig().runAnywhere.modelId
Task {
do {
// Attempt to load from local cache first
try await RunAnywhere.loadModel(modelId)
print("Model loaded from cache")
} catch {
// Not cached — download the GGUF from HuggingFace
let progressStream = try await RunAnywhere.downloadModel(modelId)
for await progress in progressStream {
print("Download: \(Int(progress.overallProgress * 100))%")
if progress.stage == .completed { break }
}
// Load into memory after download
try await RunAnywhere.loadModel(modelId)
print("Model downloaded and loaded")
}
}
}The `AsyncSequence`-based progress stream fits naturally into Swift Concurrency. You can pipe progress.overallProgress directly into a @Published property to drive a progress bar in SwiftUI — no callbacks, no delegates.
Generating Coaching Reports with Streaming Inference
The core of the RunAnywhere integration is `RunAnywhere.generateStream()` — an async streaming API that yields tokens as they’re generated, enabling a typewriter-effect UI without any extra work.
Full Coaching Summary (RiteAI Tab)
In `AIAnalysisAction.swift`, we generate a complete structured coaching report from the player’s session data:
@MainActor
private func executeWithRunAnywhere(appConfig: AppConfig) async -> AISummary? {
do {
let fullPrompt = summaryConfig.instructions + "\n\n" + buildPrompt()
var accumulated = ""
let result = try await RunAnywhere.generateStream(
fullPrompt,
options: LLMGenerationOptions(maxTokens: 600)
)
// Stream tokens as they arrive
for try await token in result.stream {
accumulated += token
}
// Parse JSON from the accumulated response
return decodeJSON(from: accumulated)
} catch {
print("RunAnywhere stream error: \(error)")
return nil
}
}The 600-token budget is enough for a rich coaching report covering overall insight, error analysis, 2–3 drill recommendations, and a motivational closing. The streaming approach means the user sees the response forming in real-time rather than waiting for a full-round-trip.
Focus Messages (Analytics Tab)
For the Analytics tab, shorter burst messages (under 15 words each) are generated per-error-type with a tighter token budget:
private static func generateWithRunAnywhere(...) async -> String {
let result = try await RunAnywhere.generateStream(
fullPrompt,
options: LLMGenerationOptions(maxTokens: 100)
)
var message = ""
for try await token in result.stream {
message += token
}
return message
}## Prompt Engineering: Structured JSON Output Without `@Generable`
Apple’s Foundation Models framework has the luxury of `@Generable` — a Swift macro that generates JSON schema from struct definitions and enforces type-safe structured output at the model level. RunAnywhere doesn’t have that (yet), so PickleRite uses **prompt-enforced JSON structure** with a custom decoder.
The Prompt (from `config.yml`)
instructions: |
You are a pickleball coach. Analyze session data and respond with ONLY a JSON object.
Do not write any text before or after the JSON. Do not use markdown. Do not explain yourself.
Output must start with { and end with }.
prompt: |
Session data:
{sessionContext}
Respond with this exact JSON structure — fill in your analysis, change nothing else:
{
“overallInsight”: “2-3 encouraging sentences about overall performance and key trend.”,
“errorAnalysis”: “2-3 prose sentences identifying top errors by frequency...”,
“recommendations”: [
{”title”: “Drill name”, “description”: “How to do the drill and what it targets.”},
{”title”: “Drill name”, “description”: “How to do the drill and what it targets.”}
],
“motivationalClosing”: “One encouraging sentence.”
}Putting the exact JSON template directly in the prompt works reliably with LFM2. The model fills in the values without modifying the structure.
Dual-Provider Architecture: RunAnywhere or Apple Foundation Models
One of the most powerful aspects of this implementation is the dual-provider model picker. Users can switch between:
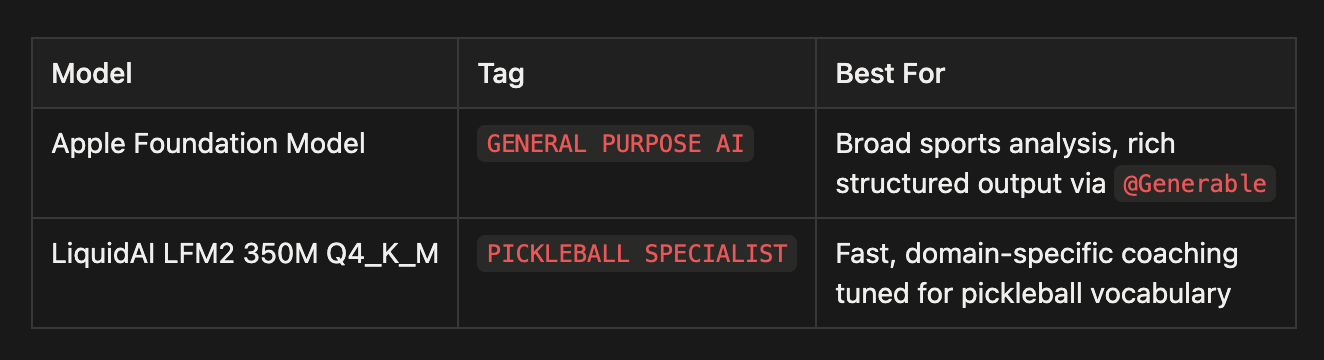
This architecture also makes A/B testing trivial — you can toggle the provider in `config.yml` and ship a build to compare output quality across a segment of users.
Why RunAnywhere Wins for a Domain-Specific Sports App
1. Any Model, Any Architecture - RunAnywhere is model-agnostic. You point it at a GGUF URL, register it, and call `generateStream`. That means as better small models emerge — whether from LiquidAI, Mistral, Meta, or the community — you swap the URL in `config.yml` and ship. No SDK updates, no API migrations.
2. Works on iOS 18+ (Not iOS 26+) - Apple’s Foundation Models framework requires iOS 26 and Apple Intelligence hardware. That’s a hard cutoff that excludes a significant portion of devices today. RunAnywhere works on **iOS 18+** — the model is downloaded once and runs via Metal, with no OS-level Apple Intelligence dependency. Your whole user base gets AI, not just early adopters.
3. Streaming Is First-Class - RunAnywhere.generateStream() returns an `AsyncThrowingStream` of tokens. It drops into Swift Concurrency’s `for try await` loop with zero boilerplate — the same idiom used throughout the app. Streaming feedback appears token-by-token, making the coaching report feel alive and responsive rather than showing a spinner followed by a wall of text.
4. Cost Is Zero Per Inference - Unlike cloud LLM APIs — where every coaching report is a billable token call — RunAnywhere inference runs entirely on the user’s device. For a consumer app where engaged players might generate coaching reports after every session, this is the difference between a sustainable business and a cost structure that scales against you.
5. Offline by Default - PickleRite players are on courts, in gyms, at outdoor facilities. Network reliability is unpredictable. After the model downloads once on a good connection, every subsequent coaching analysis works offline — no spinner, no “check your connection” error, no degraded experience.
6. Privacy Without a Privacy Policy Footnote - Session data — mistake counts, playing patterns, improvement trajectories — stays on the device. It never leaves. There’s no data retention policy to write, no GDPR or CCPA compliance burden for AI inference, and no user trust to earn around “we send your data to an AI provider.”
Getting Started with RunAnywhere
If you’re building a domain-specific iOS app and want to integrate on-device LLM inference, the RunAnywhere SDK is a remarkably low-friction path. The three key calls you need to know:
// 1. Initialize
try RunAnywhere.initialize(apiKey:, baseURL:, environment:)
LlamaCPP.register()
// 2. Register your model (any GGUF from HuggingFace or your CDN)
RunAnywhere.registerModel(id:, name:, url:, framework: .llamaCpp, memoryRequirement:)
// 3. Load and generate
try await RunAnywhere.loadModel(modelId)
let stream = try await RunAnywhere.generateStream(prompt, options: LLMGenerationOptions(maxTokens: 200))
for try await token in stream.stream { /* render token */ }Experience
Conclusion
RunAnywhere SDK gave PickleRite something no cloud AI provider could: **an AI coach that runs everywhere, costs nothing per inference, and keeps your data yours**. By pairing RunAnywhere with LiquidAI’s LFM2 350M — a small, quantized model fine-tuned for instruction following — we got coaching output that is fast, domain-specific, and available offline to every player regardless of iOS version.
For iOS developers building apps where domain expertise matters more than raw model scale, RunAnywhere is worth serious attention. You choose the model, you own the inference, and your users get AI that feels native — because it is.
PickleRite is available on the App Store. Built with SwiftUI, SwiftData, RunAnywhere SDK, and a lot of time on the court.